引言:为什么你的大模型需要“外接大脑”?
大家好,我是你们的AI伙伴狸猫算君~。今天我们要聊一个能让ChatGPT、文心一言等大语言模型真正“为你所用”的杀手级技术——RAG(检索增强生成)。
想象一下这个场景:你是一家医疗科技公司的产品经理,想用大模型回答患者关于药品说明书的问题。直接问ChatGPT“阿司匹林的禁忌症有哪些?”它可能会给你一个笼统的答案,但无法精确到你公司特定剂型、特定批次的药品信息。这时候,RAG技术就派上用场了。
RAG的本质很简单:给大模型接一个“外部知识库” 。当用户提问时,系统先从这个专属知识库中查找最相关的资料,然后把“标准答案片段”和问题一起喂给大模型,让它基于你的资料生成回答。这样既能保持大模型的流畅对话能力,又能确保回答的专业性和准确性。
这项技术正在改变各行各业:
- 企业客服:接入产品手册、售后政策,回答零误差
- 法律咨询:基于最新法规库提供参考意见
- 教育辅导:围绕指定教材内容进行答疑
- 个人助手:结合你的笔记、邮件、聊天记录提供个性化服务
接下来,我会用最直白的语言拆解RAG的工作原理,并给你一套可操作的实现方案。
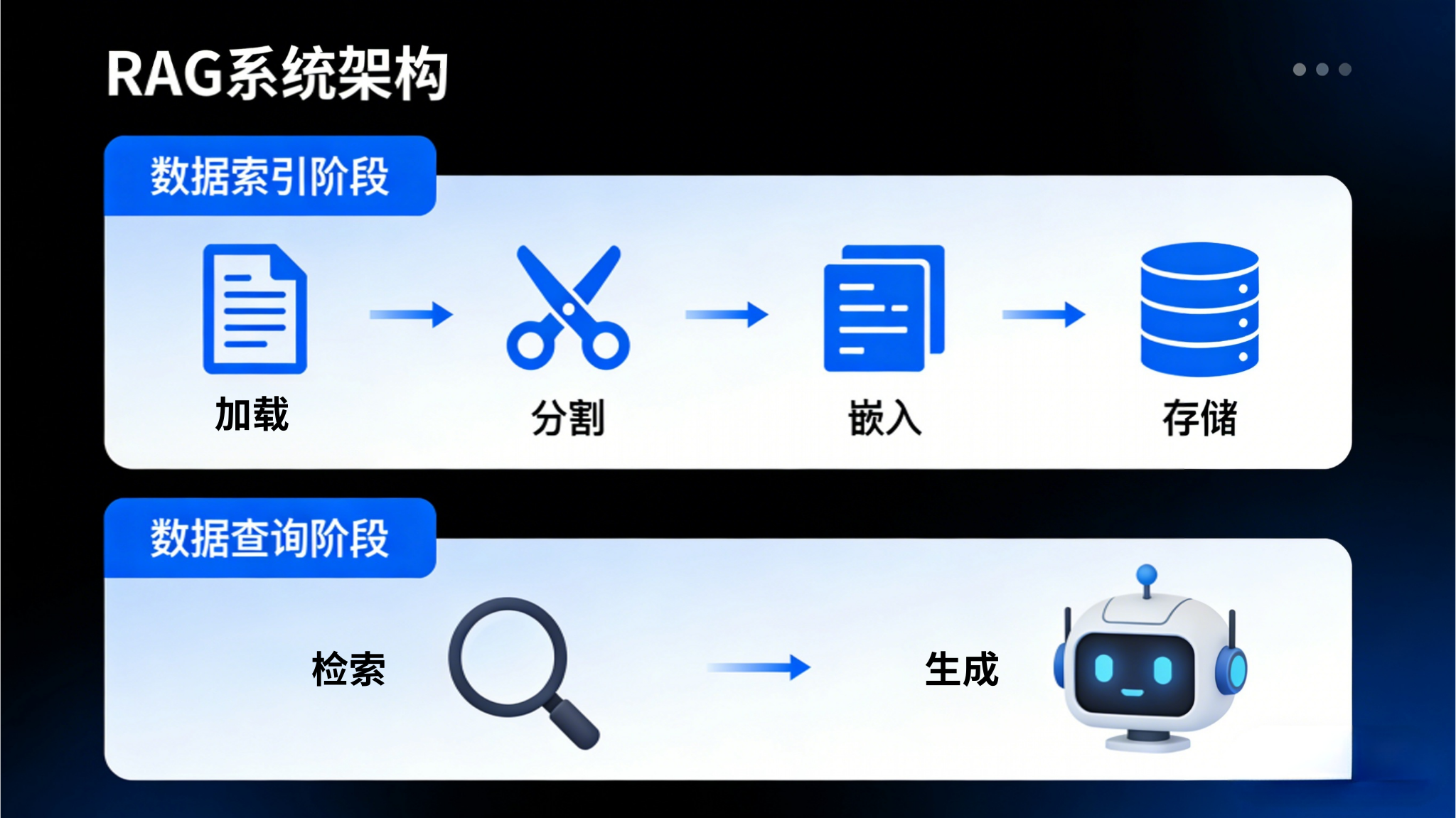
一、技术原理:RAG如何给AI“喂小抄”?
1.1 核心流程比喻
把RAG系统想象成一位“开卷考试”的学霸:
- 考试前(索引阶段) :把教材重点整理成便签(知识块),贴上智能标签(向量化)
- 考试中(查询阶段) :听到题目后快速翻阅便签(检索),找到相关段落,组织成答案(生成)
1.2 关键技术点拆解
① 文本如何变成“数学向量”?
这就是“嵌入(Embedding)”过程。举个例子:
-
原始句子:“猫咪喜欢玩毛线球”
-
经过嵌入模型处理 → 变成一串数字,比如:[0.23, -0.45, 0.87, ..., 0.12](通常是768或1024维)
-
神奇之处:相似含义的句子,其向量在数学空间里“距离很近”
- “猫爱玩绒线球”的向量会与上面句子向量很接近
- “狗狗啃骨头”的向量则会距离较远
常用嵌入模型:OpenAI的text-embedding-3-small、BGE(智源)、M3E(国产优等生)
② 为什么需要“切块(Chunking)”?
如果把整本《三国演义》作为一个知识块:
- 搜索“诸葛亮借东风”时,会返回整本书的向量
- 大模型需要从50万字里找相关段落,效率极低
合理的切块策略(如每段500字,重叠50字)能让检索更精准。就像查字典时,我们不需要翻出整本《现代汉语词典》,直接找到“J”开头的页面即可。
③ 向量数据库:AI界的“最强大脑”记忆库
传统数据库按“关键词”查找(比如搜索“苹果”返回所有含这个词的记录)。向量数据库则按“语义”查找:
- 你问:“水果之王是什么?”
- 即使知识库里没有“水果之王”这个词,但因为有“榴莲营养丰富,被誉为热带水果之王”这段文本
- 系统通过向量相似度计算,依然能准确召回这段内容
主流向量数据库:Pinecone(云端)、Qdrant(开源)、Milvus(国产优秀)
④ 大模型如何“融合”检索结果?
这是最后一步,也是体现技术水准的关键。好的Prompt设计能让大模型:
- 优先使用检索内容:“请主要参考以下资料回答”
- 诚实告知局限性:“如果资料未提及,请说明不清楚”
- 保持回答风格:“用口语化的中文,分点列出”
一个糟糕的Prompt可能导致大模型无视你的资料,继续“自由发挥”。
二、实践步骤:从零搭建你的第一个RAG系统
2.1 环境准备(Python版本)
python
# 基础依赖安装
pip install langchain==0.1.0 # RAG框架
pip install chromadb==0.4.22 # 向量数据库(轻量级)
pip install sentence-transformers==2.2.2 # 嵌入模型
pip install openai==1.3.0 # 调用GPT
2.2 完整代码实现(带详细注释)
python
import os
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI# 步骤1:加载你的知识文档
def load_documents(folder_path):"""加载指定文件夹下的所有txt文档"""documents = []for filename in os.listdir(folder_path):if filename.endswith('.txt'):file_path = os.path.join(folder_path, filename)loader = TextLoader(file_path, encoding='utf-8')documents.extend(loader.load())print(f"✅ 已加载 {len(documents)} 个文档")return documents# 步骤2:智能切分文本
def split_documents(documents):"""将长文档切分为适宜检索的小块"""text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, # 每个块约500字符chunk_overlap=50, # 块之间重叠50字符,避免截断完整句子separators=["\n\n", "\n", "。", "?", "!", ";"] # 按中文标点分割)chunks = text_splitter.split_documents(documents)print(f"📚 文档已切分为 {len(chunks)} 个知识块")return chunks# 步骤3:向量化并存储
def create_vector_store(chunks):"""创建向量数据库"""# 使用开源的嵌入模型(无需API Key)embeddings = OpenAIEmbeddings(model="text-embedding-ada-002",openai_api_base="https://api.openai.com/v1")# 创建向量存储vector_store = Chroma.from_documents(documents=chunks,embedding=embeddings,persist_directory="./my_rag_db" # 本地保存)vector_store.persist()print("🎯 向量数据库构建完成")return vector_store# 步骤4:搭建问答链
def build_qa_chain(vector_store):"""创建问答系统"""# 初始化大模型(这里用GPT-3.5,可替换为其他模型)llm = OpenAI(temperature=0.1, # 低随机性,确保答案稳定model_name="gpt-3.5-turbo")# 创建检索器retriever = vector_store.as_retriever(search_type="similarity",search_kwargs={"k": 3} # 每次检索前3个相关块)# 构建问答链qa_chain = RetrievalQA.from_chain_type(llm=llm,chain_type="stuff", # 简单合并检索结果retriever=retriever,return_source_documents=True, # 返回来源文档,方便调试chain_type_kwargs={"prompt": """你是一个专业的助手,请严格根据提供的上下文回答问题。上下文:{context}问题:{question}要求:1. 如果上下文中有明确答案,请基于上下文回答2. 如果上下文信息不足,请说“根据现有资料,我无法完整回答这个问题”3. 回答请使用简洁明了的中文,分点陈述4. 不要编造上下文之外的信息回答:"""})return qa_chain# 主函数:完整流程
def main():# 1. 准备知识库(示例:创建一个药品说明文档)with open("./knowledge/medicine.txt", "w", encoding="utf-8") as f:f.write("""【药品名称】阿司匹林肠溶片
【成分】每片含阿司匹林100mg
【适应症】用于缓解轻度或中度疼痛,如头痛、牙痛、肌肉痛。
【禁忌症】1. 对阿司匹林过敏者禁用。2. 活动性消化道溃疡患者禁用。3. 妊娠最后三个月禁用。
【用法用量】成人一次1-2片,一日3次。饭后服用。
【贮藏】密封,在干燥处保存。""")# 2. 执行RAG全流程documents = load_documents("./knowledge")chunks = split_documents(documents)vector_store = create_vector_store(chunks)qa_chain = build_qa_chain(vector_store)# 3. 测试查询questions = ["阿司匹林肠溶片的禁忌症有哪些?","这个药应该怎么保存?","孕妇可以服用吗?"]for question in questions:print(f"\n❓ 用户提问:{question}")result = qa_chain({"query": question})print(f"🤖 AI回答:{result['result']}")print("📖 参考来源:")for i, doc in enumerate(result['source_documents'][:2]):print(f" {i+1}. {doc.page_content[:100]}...")if __name__ == "__main__":main()
2.3 进阶优化技巧
技巧1:优化检索效果
python
# 混合检索策略:同时使用向量检索+关键词检索
from langchain.retrievers import EnsembleRetriever
from langchain.retrievers import BM25Retriever# 创建关键词检索器
bm25_retriever = BM25Retriever.from_documents(chunks)
bm25_retriever.k = 2# 创建向量检索器
vector_retriever = vector_store.as_retriever(search_kwargs={"k": 2})# 组合检索器
ensemble_retriever = EnsembleRetriever(retrievers=[bm25_retriever, vector_retriever],weights=[0.5, 0.5] # 各占50%权重
)
技巧2:处理长文档
python
# 分级索引:先检索章节,再检索具体内容
hierarchical_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, # 大块:用于章节检索chunk_overlap=200,separators=["\n# ", "\n## ", "\n### ", "\n\n"]
)small_splitter = RecursiveCharacterTextSplitter(chunk_size=500, # 小块:用于详细检索chunk_overlap=50
)
如果你觉得代码实现太复杂,或者想快速验证业务场景,可以尝试LLaMA-Factory Online低门槛大模型微调平台。它提供了一个可视化界面,让你能像搭积木一样构建RAG系统:
- 直接上传你的PDF/Word文档
- 选择合适的切块策略和嵌入模型
- 配置大模型参数
- 一键测试问答效果
无需编写代码,30分钟内就能跑通完整流程,特别适合产品经理、业务专家快速验证想法。
三、效果评估:你的RAG系统达标了吗?
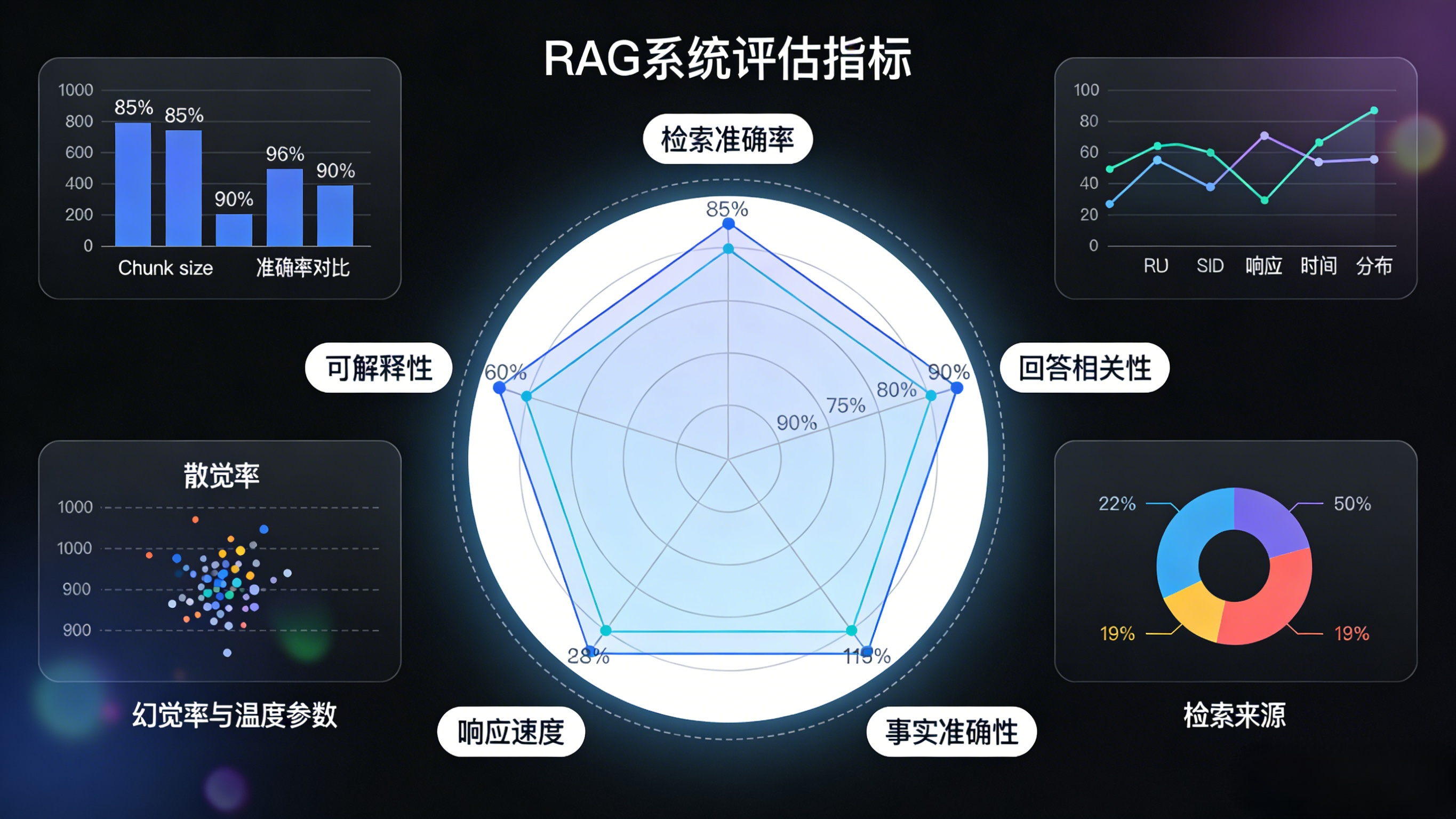
3.1 量化评估指标
| 指标 | 计算方法 | 合格标准 |
|---|---|---|
| 检索准确率 | (相关文档被检索到的数量) / (总共相关文档数) | >85% |
| 回答相关性 | 人工评分:回答是否紧扣问题 | 4分以上(5分制) |
| 事实准确性 | 对比标准答案,检查关键事实是否正确 | 零错误 |
| 响应时间 | 从提问到收到回答的总时长 | <3秒(简单查询) |
3.2 实用评估脚本
python
def evaluate_rag_system(qa_chain, test_cases):"""自动评估RAG系统test_cases格式:[{"question": "...", "expected_answer": "..."}]"""results = []for test in test_cases:# 获取回答response = qa_chain({"query": test["question"]})answer = response["result"]# 简单相似度评估(实际应用中可用更复杂的NLP评估)score = calculate_similarity(answer, test["expected_answer"])# 检查是否有“幻觉”(编造信息)has_hallucination = check_hallucination(answer, response["source_documents"])results.append({"question": test["question"],"score": score,"has_hallucination": has_hallucination,"retrieved_docs": len(response["source_documents"])})# 输出评估报告avg_score = sum(r["score"] for r in results) / len(results)hallucination_rate = sum(1 for r in results if r["has_hallucination"]) / len(results)print(f"📊 评估报告:")print(f"平均得分:{avg_score:.2%}")print(f"幻觉比例:{hallucination_rate:.2%}")print(f"平均检索文档数:{sum(r['retrieved_docs'] for r in results)/len(results):.1f}")return results
3.3 常见问题诊断表
如果你的RAG效果不佳,可以按此排查:
| 症状 | 可能原因 | 解决方案 |
|---|---|---|
| 回答与文档无关 | 检索召回率低 | 1. 调整chunk大小 2. 使用混合检索 3. 优化嵌入模型 |
| 回答不完整 | 上下文窗口不足 | 1. 压缩检索结果 2. 使用Map-Reduce策略 3. 升级大模型版本 |
| 回答包含错误信息 | 大模型“幻觉” | 1. 加强Prompt约束 2. 添加事实校验模块 3. 降低temperature参数 |
| 响应速度慢 | 检索或生成耗时 | 1. 缓存频繁查询 2. 异步处理流程 3. 优化向量索引 |
四、总结与展望:RAG的未来在哪里?
4.1 技术趋势
2024年RAG发展的三个方向:
-
智能化检索
- 多轮对话感知:基于对话历史动态调整检索策略
- 主动式检索:预测用户潜在需求,提前检索相关信息
-
端到端优化
- 检索器与生成器联合训练,让它们“互相适应”
- 统一评估指标,避免检索与生成目标冲突
-
多模态扩展
- 从纯文本走向图像、表格、音视频的跨模态检索
- 比如:上传产品设计图,检索相似竞品资料
4.2 RAG vs 微调:如何选择?
这是很多开发者困惑的问题。简单来说:
-
选择RAG当:
- 知识需要频繁更新(如新闻、政策)
- 不想重新训练模型(节省算力成本)
- 需要透明化答案来源(可解释性要求高)
- 知识库规模极大(TB级别)
-
选择微调当:
- 领域术语、写作风格需要深度适配
- 任务模式固定且复杂
- 对响应延迟要求极高(端到端更快)
- 数据安全要求不允许外部检索
实际上,RAG和微调可以强强联合。比如在LLaMA-Factory Online平台上,你可以:
- 先用RAG快速验证业务场景
- 收集高质量的问答对数据
- 对基础模型进行轻量级微调(LoRA技术)
- 让模型既拥有领域知识,又具备理想的回答风格
这种“RAG先行,微调跟进”的策略,能最大化投入产出比,特别适合中小企业。
4.3 给初学者的行动建议
如果你刚接触RAG,我建议的成长路径是:
第一周:理解原理
- 复现本文的代码示例
- 用你自己的文档创建小型知识库
第二周:掌握工具链
- 学习LangChain等框架的高级功能
- 尝试不同的向量数据库
第三周:解决实际问题
- 选择一个你熟悉的垂直领域(如法律、医疗、教育)
- 构建一个可用的原型系统
长期:关注前沿
- 订阅相关论文(arXiv上检索"RAG")
- 参与开源项目贡献
- 在真实业务中持续迭代
4.4 资源推荐
开源项目:
- LangChain:RAG开发框架
- LlamaIndex:专注于数据连接
- Chroma:轻量级向量数据库
学习资料:
- 官方文档:永远是最好的起点
- 实践课程:Coursera的"LangChain for LLM Applications"
- 技术博客:我的专栏会持续更新RAG实战案例
最后的思考
RAG技术正在降低大模型的应用门槛。过去需要投入数百万训练专属模型的企业,现在可以用极低的成本构建“知识增强型AI助手”。这项技术的本质是承认大模型不是万能的,但我们可以用工程方法让它变得足够好用。
随着工具链的成熟,未来RAG开发会像今天搭建网站一样普及。我建议每个AI从业者都应该掌握这项“给AI接外挂”的核心技能。
记住:最好的技术不是最复杂的,而是最能解决实际问题的。 RAG正是这样的技术——它用相对简单的架构,解决了大模型“一本正经胡说八道”的关键痛点。
如果你在实践过程中遇到问题,欢迎在评论区留言。我会选取典型问题在后续文章中专门解答。